
코딩딩딩
[개념정리] Encoder, Decoder, Image-Captioning 본문
1. 인코더 - 디코더
인코더는 입력 데이터를 임베딩으로 변환하여 고차원적 표현을 생성하고, 디코더는 이를 기반으로 문맥에 맞는 출력을 생성한다.
<인코더>
• 영상 인코더
입력 영상에서 필수적인 시각적 특징을 추출하여 임베딩 또는 잠재 표현이라 불리는 고정된 크기의 벡터로 변환한다.
CNN, ViT가 주로 사용된다.
• 언어 인코더
텍스트를 숫자 표현으로 변환하고 문맥 정보를 캡처하여 고정된 크기의 임베딩 벡터를 생성한다.
과거에는 LSTM, GRU, RNN이 사용되었으나, 현재는 Self-Attention 기반 BERT, Transformers와 같은 모델이 주로 사용된다.
<디코더>
• 영상 디코더
고정된 크기의 임베딩 벡터를 입력으로 받아 전체 해상도 이미지를 생성한다.
과거에는 CNN, VAE, GAN이 주로 사용되었으며, 현재는 Transformer 및 Diffusion Models이 활용된다.
• 언어 디코더
입력 정보를 기반으로 토큰의 시퀀스를 생성한다.
RNN 기반 모델은 토큰을 왼쪽에서 오른쪽으로 한 번에 하나씩 순차적으로 처리한다.
Transformer 기반 모델은 병렬 처리로 계산 효율성을 높인다.
<인코더와 디코더의 결합>
• 이미지 캡션: 영상 인코더와 언어 디코더 결합
• 텍스트 프롬프트 기반 영상 생성: 언어 인코더와 영상 디코더 결합
• 시각적 질문 답변, VAQ: 영상 인코더, 언어 인코더, 언어 디코더 결합
<컨텍스트 디코딩>
• 텍스트 디코딩
RNN, 트랜스포머 기반 모델을 사용한다.
디코더는 각 단어를 한 번에 하나씩 예측하며, 시퀀스에서 이미 생성된 단어를 조건으로 사용한다.
• 영상 디코딩
GAN, VAE 기반 모델을 사용한다.
생성된 이미지가 컨텍스트와 일치하고 원하는 시각적 특성을 나타내도록 보장한다.
2. Image Captioning
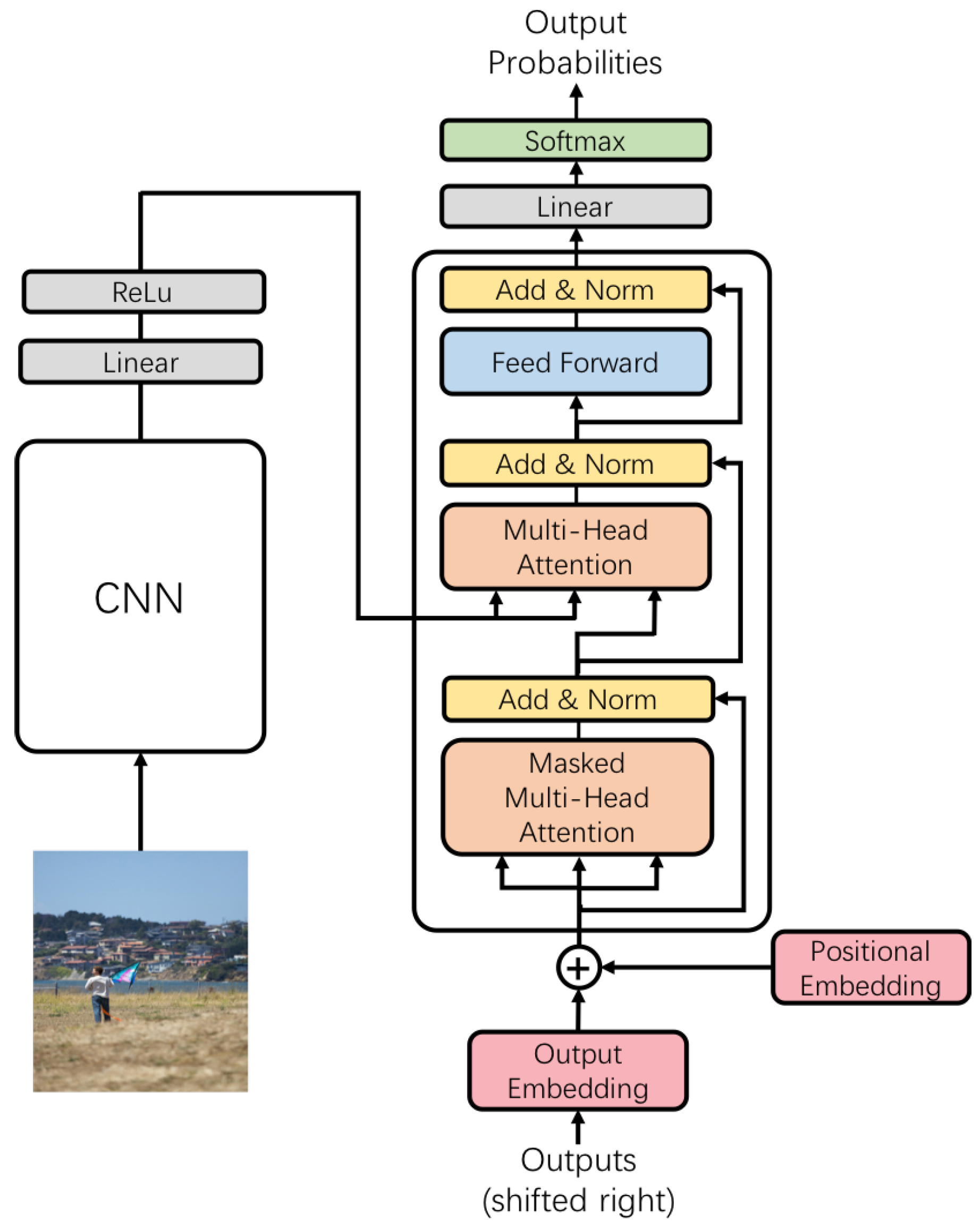
CNN과 같은 영상 인코더와 RNN, Transformer와 같은 언어 디코더를 결합하여 영상에 대한 설명이 포함된 텍스트 캡션을 생성하는 작업이다.
<주요 구성 요소>
• 영상 인코더: 입력 영상을 처리하여 시각적 정보를 캡처하는 높은 수준의 임베딩 추출한다.
• 언어 디코더: 인코딩 된 영상 정보를 가져와 텍스트 설명을 생성한다.
• 컨텍스트 벡터: 영상 콘텐츠를 요약하는 고정된 크기의 숫자 표현으로, 디코더의 입력으로 사용된다.
• 어텐션 메커니즘: 디코더가 캡션의 단어를 생성할 때 영상의 다른 부분에 집중할 수 있도록 지원한다.
• 언어 모델: 일관성 있고 문맥과 관련된 텍스트를 생성하는데 도움을 준다.
• 평가지표: BLEU, ROUGE와 같은 지표로 생성된 텍스트 캡션의 품질을 평가한다.
<응용 사례>
• 시각 장애인을 위한 시각 보조 도구: 주변 환경을 설명하여 이동과 상호작용을 돕는다.
• 시각적 데이터에 대한 텍스트 설명 생성: 데이터 관리 및 분류에 유용하다.
• 이미지 기반 콘텐츠 색인 및 검색: 텍스트 캡션을 활용해 이미지 검색 효율성을 높인다.
• 소셜 미디어 콘텐츠 강화: 자동 텍스트 생성으로 이미지와 함께 제공되는 콘텐츠 품질을 향상한다.
• 의료 영상 분석 보고서: 의료 영상 데이터를 설명하며 진단 과정에 기여한다.
• 교육용 영상에 텍스트 포함 제공: 학습 자료의 가독성과 이해를 돕는다.
• 보안 카메라 영상 설명: 보안 상황의 해석 및 요약 제공한다.
<주요 과제>
• 정교한 물체 인식 능력 필요: 복잡한 이미지 내 물체와 장면을 정확히 이해해야 한다.
• 장거리 종속성 문제: 긴 문장 생성 시 문맥과 일관성을 유지하기 어렵다.
• 이미지 모호성 처리 문제: 이미지의 불명확하거나 중의적인 요소를 해결해야 한다.
'인공지능 > 개념' 카테고리의 다른 글
| [개념정리] 언어 명령 기반 영상 생성 트랜스포머, 생성모델 유형, Diffusion Model (2) | 2024.12.17 |
|---|---|
| [개념정리] Stable Diffusion, DALL-E, DALL-E 2 (0) | 2024.12.16 |
| [개념 정리] GAN, Generative Network (2) | 2024.12.09 |
| [개념정리] Word Embedding, Self-Attention, Language Transformer (0) | 2024.12.08 |
| [개념정리] Image patch embedding, Vision Transformer, U-net (0) | 2024.12.07 |



