
목록인공지능 (8)
코딩딩딩
 [개념정리] BERT, GPT, Fine-Tuning
[개념정리] BERT, GPT, Fine-Tuning
1. BERT - Bidirectional Encoder Representations from TransformersBERT는 양방향 인코더 트랜스포머로, 대규모 텍스트 데이터에 대해 사전 학습을 수행한 후, 특정 다운스트림 작업에 적용하는 자연어 처리 모델이다.- 양방향 학습: 문맥을 양방향으로 이해하며, 문장 구조와 의미를 깊이 파악할 수 있다. - 사전 학습 후 Fine-tuning: 대규모 텍스트 데이터로 사전 학습을 한 후, 관심 있는 작업에 맞춰 모델을 Fine-tuning 한다. - Masked Language Model: 입력 데이터의 일부를 마스킹하여 예측하는 방식으로 구현된다.BERT는 입력 데이터를 다음의 세 가지 임베딩으로 변환한다. - 토큰 임베딩: 단어 벡터를 생성하며, 후속 분..
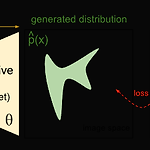 [개념정리] 언어 명령 기반 영상 생성 트랜스포머, 생성모델 유형, Diffusion Model
[개념정리] 언어 명령 기반 영상 생성 트랜스포머, 생성모델 유형, Diffusion Model
1. 언어 명령 기반 영상 생성 트랜스포머 영상 생성 트랜스포머는 언어와 영상 데이터를 결합해 명령에 따라 영상을 생성하는 딥러닝 모델이다. 실제 환경이나 3D 시뮬레이션 등 다양한 상황에서 사용될 수 있다. • 언어 처리 부분: Language Encoder Transformer 기반 언어 모델을 사용해 텍스트 명령을 임베딩 벡터로 변환한다. • 시각 정보 처리 부분: Visual Encoder CNN과 Transformer를 결합해 입력된 영상 데이터를 feature로 변환한다. • 트랜스포머 인코더 Language Encoder와 Visual Encoder에서 나온 feature를 결합하여 트랜스포머 인코더 레이어를 통과시켜 융합된 Language-Visual feature를 추출한다...
 [개념정리] Stable Diffusion, DALL-E, DALL-E 2
[개념정리] Stable Diffusion, DALL-E, DALL-E 2
1. Stable Diffusion잠복 확산 모델을 기반으로 하며, 사전 학습된 자동 인코더를 활용해 구조화된 잠재 공간에서 고품질 이미지를 효율적으로 생성한다.[1] VAE 인코딩: 압축 단계VAE 인코더는 픽셀 공간의 입력 이미지를 저 차원의 잠재 공간으로 압축하며, 이 과정에서 이미지의 필수적인 의미 정보를 캡처한다. [2] 포워드 확산: 노이즈 추가잠재 공간 표현에 가우시안 노이즈를 반복적으로 추가하여, 무작위성과 다양성을 부여한다. [3] 역확산: 노이즈 제거포워드 확산 과정과 반대 방향으로 동작하여, 잠재 공간에서 노이즈를 제거하고 깨끗하고 안정적인 잠재 표현을 생성한다. [4] VAE 디코딩: 복원 단계VAE 디코더는 정제된 잠재 표현을 픽셀 공간으로 변환하여 최종 이미지를 생성한다.2. ..
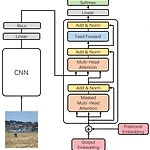 [개념정리] Encoder, Decoder, Image-Captioning
[개념정리] Encoder, Decoder, Image-Captioning
1. 인코더 - 디코더 인코더는 입력 데이터를 임베딩으로 변환하여 고차원적 표현을 생성하고, 디코더는 이를 기반으로 문맥에 맞는 출력을 생성한다. • 영상 인코더 입력 영상에서 필수적인 시각적 특징을 추출하여 임베딩 또는 잠재 표현이라 불리는 고정된 크기의 벡터로 변환한다. CNN, ViT가 주로 사용된다. • 언어 인코더 텍스트를 숫자 표현으로 변환하고 문맥 정보를 캡처하여 고정된 크기의 임베딩 벡터를 생성한다. 과거에는 LSTM, GRU, RNN이 사용되었으나, 현재는 Self-Attention 기반 BERT, Transformers와 같은 모델이 주로 사용된다. • 영상 디코더 고정된 크기의 임베딩 벡터를 입력으로 받아 전체 해상도 이미지를 생성한다. 과거에는 CNN, VAE, GAN이 주로 ..
 [개념 정리] GAN, Generative Network
[개념 정리] GAN, Generative Network
1. 생성적 적대 신경망 - Generative Adversarial Network, GANGAN은 생성자와 판별자로 구성된 머신 러닝 프레임워크이다. 이 두 네트워크는 서로 경쟁하며, 고품질의 합성 데이터 생성을 목표로 한다.- 구성요소생성자: 이미지, 텍스트와 같은 합성 데이터 인스턴스를 생성하며, 판별자를 속이는 것을 목표로 한다. 판별자: 실제 데이터와 생성된 데이터를 구분하며, 생성자의 개선을 유도한다. 생성자와 판별자간의 상호작용을 반복하며, 이를 통해 생성자는 더 정교한 데이터를 생성하고, 판별자는 더 정확하게 구별할 수 있도록 학습한다.- 반복 훈련 단계[1] 데이터 생성: 생성자가 합성 데이터를 생성한다. [2] 판별자의 판단: 판별자가 각 샘플이 진짜인지 가짜인지 판단한다. [3] 피..
 [개념정리] Word Embedding, Self-Attention, Language Transformer
[개념정리] Word Embedding, Self-Attention, Language Transformer
1. Word embedding단어를 고차원 벡터 공간에서 밀도가 높은 벡터로 표현하는 기술이다. 단어 간의 의미 관계를 포착하여 의미적으로 유사한 단어를 유사한 벡터로 표현한다.- 단어 표현 방법 종류• One-hot encoding 단어와 같은 범주형 데이터를 숫자로 표현하는 기법. 각 단어는 고차원의 벡터 공간에서 하나의 1과 나머지 0으로 표현된다. 단점으로는 의미론적 관계가 부족하고 계산이 비효율적이다. • Bag-of-Words, BoW 텍스트에서 단어의 빈도를 계산하여 문서나 문장을 벡터로 변환한다. 어순, 문맥은 무시하며 단어 간의 의미 관계를 포착하지 못한다. • TF-IDF, Term Frequency - Inverse Document Frequency 문서에 자주 등장하지만 말뭉치에서..