
코딩딩딩
[논문리뷰] Interpretable stock price forecasting model using genetic algorithm-machine learning regressions and best feature subset selection((2)) 본문
[논문리뷰] Interpretable stock price forecasting model using genetic algorithm-machine learning regressions and best feature subset selection((2))
komizke 2024. 8. 21. 19:134. Experimental results and discussion
4.1. Data description and experimental environment
Internal Features: 2010.01.04 ~ 2021.12.30 기간에 대해
XOM 주식에 대해 ‘High’, ‘Low’, ‘Open’, ‘Close’, ‘Volume’을 가져온다.
External Features: 2018.01.04 ~ 2021.12.30 기간에 대해
세계 주식시장 지수, 동일업종내 경쟁기업, 유가 지표, 재생에너지 섹터내 경쟁기업에서
가격 데이터를 가져온다.


4.2. Internal feature set expansion
Internal features에서 null값과 'Close'값을 제거하고 67개의 Technical indicators를 추가하여
training dataset((80%)), testing dataset((20%))으로 나눈다.
Training dataset의 85%는 GA-ML 회귀 알고리즘 학습, 15%는 학습된 모델의 검증을 위해 구분한다.
Testing dataset은 Optimal feature set의 성능 평가를 위해 사용된다.
정규화를 통해 데이터의 범위 $[0,1]$로 설정한다.
4.3. Analysis of internal feature set
Internal features를 입력으로 하여 GA-ML 회귀 알고리즘을 통해 Important feature sets 선택
아래는 다섯 개의 GA-ML 회귀 알고리즘 결과이다.
성능은 RMSE 점수로 평가하여 업데이트한다.

Best RMSE 값이 XGBoost는 0.00129, LightGBR은 0.01972으로 다른 알고리즘보다 우수한 값이 나왔다.
Validation RMSE측면에서 ExtraTrees, DecisionTree, RandomForest에서 비슷한 값들이 나왔으며 XGBoost와 LightGBR이 상대적으로 우수한 결과가 나왔다.

아래 표는 GA-ML 회귀 알고리즘별 Importance score를 기준으로 하는 Top10 feature를 나타낸다.

알고리즘에 따라 feature의 Importance score가 다르며
특히 '5WclPrice'는 XGBoost, ExtraTrees, RandomForest, LightGBR에서
the most important featrue로 나타난다.
Important Score Filtering((ISF))를 위해
cut-off 값을 0.1로 설정하여 Optimal feature sets를 선택한다.
Optimal Features
‘5TypPrice’, ‘5WclPrice’, ‘5AvgPrice’, ‘5MedPrice’, ‘Low’, ‘1Dema10’ ,‘2Bop’
Internal optimal features와 XOM 주식의 'Close'값 사이에 대해
선형 관계 여부를 결정하기 위해 상관관계 계수 $r$를 측정한다.
'2Bop'을 제외하고 모두 강한 상관관게를 보인다.

7개의 Optimal features으로부터 127개의 non-empty subsets을 만들어서
다섯개의 GA-ML 회귀를 통해 RMSE 점수를 기준으로 Best feature subset을 선택한다.

(2Bop,5WclPrice)는 세 개의 알고리즘에서 best subset으로 선택되었다.
'2Bop'은 가장 낮은 상관관계 계수 값을 갖고 있었지만,
'5WclPrice'와 결합할 때 best feature subset을 형성하는 특징이 존재한다.
테스트 데이터를 활용하여 5개의 GA-ML 회귀에 대해 RMSE값을 측정한다.

Features set이 Optimal features subset에서 Best feature subset으로 변할수록
성능이 향상됨을 확인할 수 있다.
아래는 LightGBR에 대해 best subset ((2Bop, 5WclPrice))를 활용한 성능 측정 결과이다.

아래는 테스트 데이터에서 best feature subset으로부터 정규화된 타겟값과 예측값의 그래프이다.

4.3.1. Performance comparison to benchmark studies

S&P500, DJIA, PetroChina, ZTE, Gold price 예측 연구에서
기존의 LSTM, XGBoost, RandomForest, LightGBR을 사용하는 것보다
하이브리화된 GA-ML 모델을 사용할 때 성능이 더 우수하다.
4.4 Analysis of external market price features
4.4.1. Global interpretation with the best subsets of external features
External features에서 train용 80%, test용 20%로 나누고
train용에서 검증용 15%, 나머지는 훈련용으로 사용한다.
STEP1. XOM의 'Close'와 external features사이에 대해
상관관계 계수 값을 측정하여 선형 관계 여부를 판단하다.
유의미한 상관관계 계수의 절대값: 0.7
XOM의 'Close'는 energy 섹터의 경쟁자 가격인 ‘RDS’, ‘CVX’, ‘BP’, ‘MRO’, ‘VLO’, ‘COP’와
energy 섹터 지수 'SPE' 사이에서 강한 선형적 상관관계 나타남.

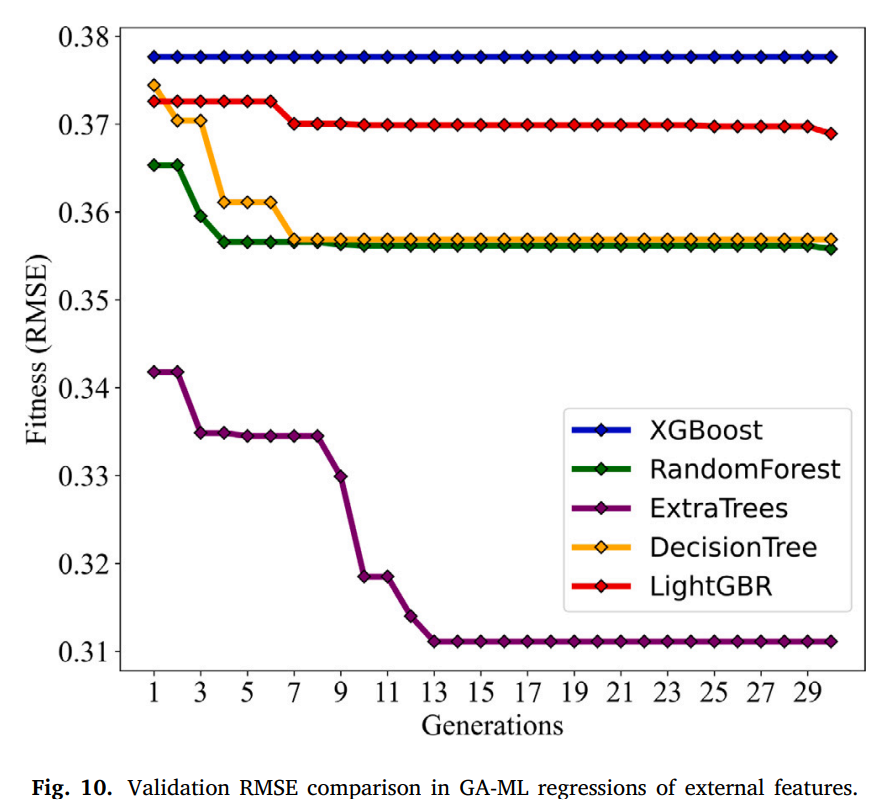
STEP2. External features에 대해 GA-ML 회귀를 실행한다.

External features에 대해서 Internal features와 다르게 ExtraTrees에서 가장 성능이 우수하며,
XGBoost의 성능이 가장 좋지 않다.
아래는 30세대를 걸쳐서 측정한 RMSE의 값의 변화를 나타내는 그래프이다.
아래는 GA-ML 회귀 종류 별로 Important score를 기준으로 한
Top10 external features를 정리한 표이다.

cut-off important score: 0.1
optimal features
‘MRO’, ‘BP’, ‘RDS’, ‘VLO’, ‘COP’, ‘SPE’
'SPE': oil, gas기업을 포함한 S&P 500 에너지 섹터 지수
나머지: XOM의 경쟁 기업
6개의 Optimal feature sets로부터 63개의 non-empty subsets을 형성하고
ML 모델별로 best feature subset을 선택한다.

((SPE, VLO))는 ExtraTrees, LightGBR, RandomForest 알고리즘에서
성능이 가장 우수한 집합이다.
아래는 Best feature subset ((SPE, VLO)) 상대로 성능이 가장 좋은 ExtraTrees의 평가 지표이다.
앞서 Internal features보다 큰 오차값이 나왔다.

4.4.2. Piecewise optimal curve fitting(POCF)
먼저 SG smoothing filter를 사용하여 타겟 데이터를 smoothing 한다.
아래는 2021.11.16 ~ 2021.12.30 기간에서
임의로 데이터 포인트를 설정하여 SG smoothing을 거친 그래프이다.

위 그래프처럼 SG smoothing filter를 거치게 되면
연속적인 곡선 형태로 바뀌고, 극단적인 값들이 제거된다.
주가 행동 분석을 위한 향상된 다항식 fitting을 위해
1차 도함수를 통해 계산된 모든 turning points를 기준으로
구간을 나누어 곡선을 그린다.
아래는 네개의 구간으로 나눈 그래프이다.
Part1: 2021.11.16 ~ 2021.11.30
Part2: 2021.12.01 ~ 2021.12.09
Part3: 2021.12.10 ~ 2021.12.16
Part4: 2021.12.17 ~ 2021.12.30

POCF의 방식은 non-segmented 방식인 Linear, Quadratic, Cubic보다 성능이 우수하다.

아래는 segmented data에 대해 최적의 다항식이다.

4.4.3. Local interpretation with the best subset of external features
아래는 data segment 별로 최적의 알고리즘과 best external feature subset을 나타낸다.

4개의 segments 중에서 3개에서 'SPE'가 포함되어 있기 때문에,
XOM과 강한 상관관계가 있는 것으로 추정할 수 있다.
4.5. Discussion on the experimental results
Internal features의 best feature subset: ((5WclPrice, 2Bop))
External features의 best feature subset: ((SPE, VLO))
POCF
네 개의 구간에서 공통적으로 선택된 feature는 'SPE'이며,
그 외 feature는 에너지 섹터 내 경쟁기업이다.
이 결과는 시간적으로 유연한 해석이 가능함을 암시한다.
5. Conclusion and future work
아직 Collective behavior of features를 측정하고 Interpretability를 평가를 위한 확립된 방법은 없다.
따라서, 정량적 평가 지표는 앞으로 개발되어야 한다.
*본 연구의 한계점 및 미래 연구 방향*
[1] Internal technical indicators, external features의 선택 기준이 충분히 연구되지 않았기에
본 연구에서 선택된 features에 대해 모호성이 존재한다.
향후 Input features에 대한 엄격한 연구가 필요하다.
[2] Human-friendly interpretability의 한가지 특성으로 사회적 속성이 있으며,
사회적 속성은 사회적 상호작용의 결과로 설명될 수 있다.
주식 시장은 '시장과 관련된 뉴스', '경제적 상황', '정치적 정책들',
'대중 감정', '다른 외부 요소들' 등과 상호작용하는 복잡한 시스템이다.
미래 연구는 감정 분석과 텍스트 분석을 포함한 Human-friendly interpretability를 발달시킬 필요가 있다.
[3] ML, DL 알고리즘을 활용하여 최적의 주식 투자 포트폴리오를 개발한다.
이는 수익률 평균을 최대화하고 수익률의 분산을 최소화하여
여러 주식에 투자하기 위한 multi-objective optimization문제이다.
[4] 본연구의 Interpretability를 human-friendly visualization와 통합한다.
현재 Interpretability 방법은 feature-importance score에 대한 simple bar를 사용한다.
최근 이미지와 텍스트 데이터에 대한 ML의 Interpretability 연구는 직관적이고
Human-friendly interpretability을 제공하기 위해
다양한 개체와 색상으로 중요한 개념을 시각화하는 것을 고급 정보로 사용한다.
[5] Collective behavior of features의 평가 지표와 Interpretability에 대한 연구가 더 필요하다.
Collective behavior of features과 시간 유연적 로컬 Interpretability 는 필요성은 인정되었지만,
Collective behavior of features 측정, Interpretability 평가를
정량적으로 진행하는 확립된 방법은 아직 존재하지 않는다.
이전 장
https://michelangeloo.tistory.com/50
[논문리뷰]Interpretable stock price forecasting model using genetic algorithm-machinelearning regressions and best feature s
* 본글의 사진과 내용은 논문을 바탕으로 작성하였습니다. 논문 출처1. IntroductionInterpretability 관점에서 ML과 DL 모델은 black-box structure를 나타낸다.Black-box structure란 입력과 출력 사이의 관계를 예
michelangeloo.tistory.com



